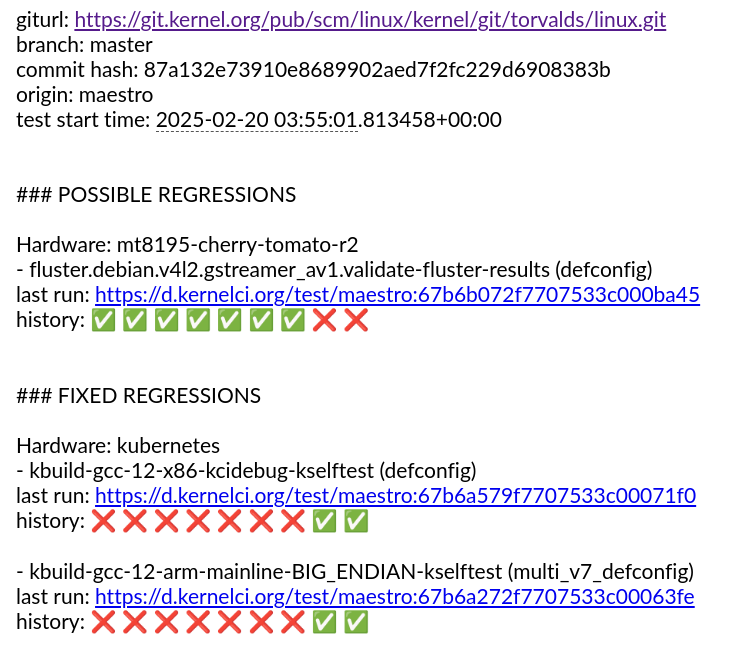
We’re excited to announce that regzbot, the Linux kernel regression tracking bot created by Thorsten Leemhuis, is joining the KernelCI project. This collaboration marks an important step forward in our shared mission to improve the quality, stability, and long-term maintenance of the Linux kernel.
About Regzbot
Regzbot is a regression tracking utility (dashboard, docs) that has become essential for the Linux kernel community. The bot allows developers and users to add regressions reports to the tracking using simple commands, such as #regzbot introduced: v6.1..v6.2-rc1. Regzbot notices those commands on various mailing lists as well as in bugzilla.kernel.org and a few other bug trackers used for kernel development. From then on regzbot watches out for replies to the tracked report as well as references to it on various mailing lists and in git trees. That way it monitors the issue’s progress on various fronts and can automatically mark tracked regression as resolved once a fix lands in the affected Linux series. By connecting and monitoring the various places relevant, regzbot acts as a kind of meta-bugtracking tool tailored for the special needs of the kernel – but is intentionally kept simple to not become yet another bug tracker.
As the Linux kernel’s regression tracker, Thorsten uses regzbot to keep an eye on regressions, which without the bot would not scale well. Regzbot thus allows Thorsten to ensure many regressions that otherwise might have been forgotten are resolved, as he prods reporters and developers when things stall according to regzbot – sometimes by involving Linus Torvalds, for example when developers do not handle regressions like the lead developer wants them to be dealt this is. Thorsten also uses regzbot to semi-automatically generate weekly reports for Linus Torvalds, which he then can use to decide whether to release a new kernel version or extend the development phase.
Regzbot and Thorsten work with it has earned the community’s trust by automating what was previously exhausting manual work while maintaining a low-overhead approach.
Why This Collaboration Matters
This partnership addresses critical needs for both projects. For KernelCI, regzbot provides the semi-automatic regression tracking we’ve needed—the ability to learn when a reported regression gets fixed and update our Dashboard accordingly. Regzbot’s strong reputation within the kernel community also creates a trustworthy path for KernelCI to report regressions to maintainers.
For the kernel community, this collaboration means regzbot will receive dedicated resources to expand its capabilities and improve its user experience, benefiting the entire kernel ecosystem.
What’s Next
Our roadmap focuses on three key areas:
Improved Architecture: We’re exploring redesigning regzbot’s scraper functionality as a standalone service that could benefit other kernel community use cases. We’ll be inviting kernel.org to participate in these discussions.
Extended scope: Regzbot will be redesigned to become more autonomous while also allowing subsystem maintainers to better stay on top of regressions in their domain with the bot’s help.
Modern User Experience: We will be creating a new interface for regzbot within the KernelCI Dashboard. This new UX will provide interactive features like filters, search, and grouping while maintaining the functionality the community relies on.
Better Integration: Once KernelCI regressions are tracked by regzbot, we’ll display relevant information directly in the Dashboard, including mail threads, bugzilla entries, git commit references, and regression status.
A Word from Thorsten Leemhuis
Regzbot was an experiment which turned out to be really successful: it has proven to be a useful tool to help ensure new Linux kernel versions work as well as their predecessors. This might sound benign, but it is not, as it is a crucial factor to make people willing to upgrade to new versions – and that is in everybody’s interest, as only those get all the security fixes and new hardening techniques to counteract current and future risks in this ever changing world. This aligns well with the goals of KernelCI, which is why it is a perfect new home for regzbot. The cooperation will furthermore empower regzbot and make it more capable, because as a team we’ll finally be able to polish and enhance regzbot to make it serve the Linux kernel users and developers a lot better than it does now.
Get Involved
We’re committed to transparent, community-driven development. Any changes will be made carefully, with thorough testing and feedback, to preserve the reliability that has made regzbot valuable.
If you’re interested in following this work:
- Visit regzbot’s interface at https://linux-regtracking.leemhuis.info/
- Check out the regzbot documentation to learn how to use it
- Join discussions in the KernelCI Discord channels
We look forward to working with Thorsten and the entire kernel community to make regression tracking even more effective.
For more information, visit https://kernelci.org and https://linux-regtracking.leemhuis.info/about/.